らずらいと兄貴の熱血プログラミング「構造体のパディング」
2017-02-21
はじめまして!!いつもハイテンションなLazuriteの助っ人こと「らずらいと兄貴」です!!
前回のらずらいと姫のブログで書いた構造体に関して、技術的に細かいのですがハマると大変な構造体のパディングとパック機能について説明します。
「構造体をバイト列として扱う」、「バイト列を構造体に変換する」ときにCPUの互換性が無くなる問題で、「パディング」として一般的に知られています。そして、この問題に直面すると原因を見つけるのが大変です。というのも、SDカードのライブラリを移植しているときにハマってしまいました。
パディングについて
構造体について前回のらずらいと姫の開発日記で説明しました。この構造体、C/C++で使用することが出来るのですが、CPUによって扱い方が異なるのです。特に、8bit CPU、16bit CPU、32bit CPUなど、ビット幅の異なるCPUで開発されたソフトウエアを移植する時には注意が必要です。
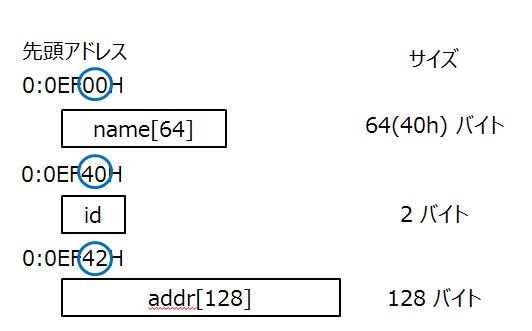
たとえば、先週の構造体の例では、
struct personal_info {
char name[64];
unsigned short id;
char addr[128];
};
というプログラムでした。
この構造体を含むプログラムをコンパイルすると、以下のようにメモリ上ではすべてのメンバ変数が連続したアドレスで配置されます。当たり前ですよね。
ですが、この当たり前がそうでないケースがあります。例えば、上記の構造体に退職されたかどうかなどを示すために、データが有効か/無効かを示すメンバ変数flagを加えたとします。
struct personal_info {
unsigned char flag; // 個人データ有効/無効フラグ★
char name[64];
unsigned short id;
char addr[128];
};
この構造体を含むプログラムを、16bit CPUでコンパイルすると、16bit幅のデータ空間が扱いやすいので1バイト分のスペースをあけて、次のデータ領域を確保します。これをパディング※と呼びます。(※英語でパディングは、詰め物とか水増しとかを意味します。)
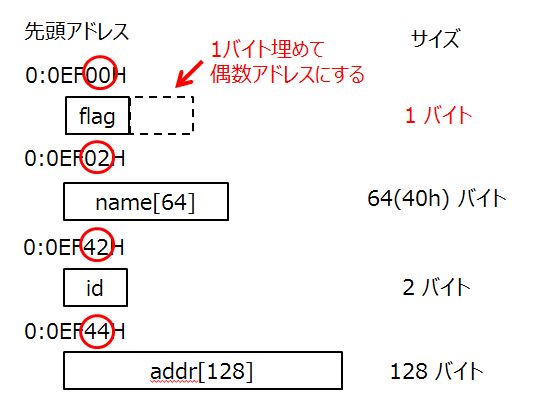
Lazuriteで使っているマイコンは16bitマイコンなので、1バイト分のデータをあけて16bit単位で処理をしたほうが早いのでこのような調整をするのですが、8bit CPUではパディングしなかったり、32bit, 64bitではビット幅に合わせたパディングをしたりします。構造体で宣言したデータを構造体のまま使用るのであれば問題は発生しませんが、連続したメモリ空間として扱うときにCPUの差が生じるので注意してください。
パック機能
次にパック機能についてです。冒頭でも書きましたが、普通のプログラムでは上記の話は特に問題になりません。ですが、以下の通信の例ではパディングが問題になります。
たとえば、以下のフォーマットで通信の相手から送ってくるケースです。通信はできるだけ 無駄なデータは送りたくないので、データは詰めて送ってくるのが一般的です。

この受信バッファの構造体を以下のように定義したのですが、preの後ろとchksumの後ろに1バイトずつのパディングが挿入されます。
struct {
uint8_t pre;
uint16_t addr;
uint32_t data;
uint8_t chksum;
} unpacked_buf;
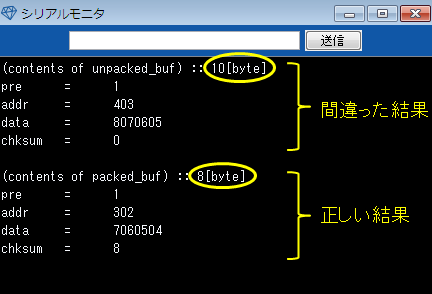
受け取ったデータを、単純に受信バッファ構造体の先頭からコピーするプログラムを書いて、実際に動かしてみると、preの後ろのパディングによってaddrの開始アドレスが1バイトずれているため、addrを含め、以降のデータにずれが生じています。
(contents of unpacked_buf) :: 10[byte] pre = 1 addr = 403 // 302が正しい★ data = 8070605 // 7060504が正しい★ chksum = 0 // 8が正しい★
そこで、この問題を解決するための方法として、パディングの挿入を抑止する(パックするといいます)機能があり、新しいLazuriteIDEパッケージ(ドライバ ver.Feb,8, 2017)からサポートされました。(※)
※詳細はCCU8ユーザーズマニュアル
C:\LazuriteIDE\bin\U8Dev\Doc\FJXTCCU8_UM-11.pdf
の「11. 構造体/共用体のパック機能」に記載されています。
使い方の例ですが、
__packed struct {
}
と構造体の定義の先頭に__packed修飾子を付けるだけです。この修飾子を付けて、改めてプログラムを動かしてみると、送受信者間のデータのずれは解消されました。
(contents of packed_buf) :: 8[byte] pre = 1 addr = 302 data = 7060504 chksum = 8
ちなみに、筆者はLazurite向けのSDカードライブラリを開発した際、まさにこの問題に直面しました。SDカードからFATフォーマットでデータを読み込んで構造体のバッファに取り込むのですが、メンバ変数を参照したときにおかしなデータが入っており、パディングが挿入されていることに気付かず、問題を解決するのに苦労しました。
今回の実験で使用したソースコードはこちらです。
[c]
#include "pack_test_ide.h" // Additional Header
struct {
uint8_t pre;
uint16_t addr;
uint32_t data;
uint8_t chksum;
} unpacked_buf;
__packed struct {
uint8_t pre;
uint16_t addr;
uint32_t data;
uint8_t chksum;
} packed_buf;
const uint8_t recv_data[] = { 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08 };
void data_copy(uint8_t *buf, const uint8_t *data, uint8_t size)
{
int i;
for (i = 0; i < size; i++ ) {
buf[i] = data[i];
}
}
void setup() {
// put your setup code here, to run once:
Serial.begin(115200);
data_copy(&unpacked_buf.pre, recv_data, sizeof(recv_data));
Serial.print("(contents of unpacked_buf) :: ");
Serial.print_long((long)sizeof(unpacked_buf), DEC);
Serial.println("[byte]");
Serial.print("pre\t = \t");
Serial.println_long((long)unpacked_buf.pre, HEX);
Serial.print("addr\t = \t");
Serial.println_long((long)unpacked_buf.addr, HEX);
Serial.print("data\t = \t");
Serial.println_long(unpacked_buf.data, HEX);
Serial.print("chksum\t = \t");
Serial.println_long((long)unpacked_buf.chksum, HEX);
Serial.println("");
data_copy(&packed_buf.pre, recv_data, sizeof(recv_data));
Serial.print("(contents of packed_buf) :: ");
Serial.print_long((long)sizeof(packed_buf), DEC);
Serial.println("[byte]");
Serial.print("pre\t = \t");
Serial.println_long((long)packed_buf.pre, HEX);
Serial.print("addr\t = \t");
Serial.println_long((long)packed_buf.addr, HEX);
Serial.print("data\t = \t");
Serial.println_long(packed_buf.data, HEX);
Serial.print("chksum\t = \t");
Serial.println_long((long)packed_buf.chksum, HEX);
}
void loop() {
// put your main code here, to run repeatedly:
}
[/c]
実行した結果がこちらです。
先頭から順番に0x01,0x02…というデータを構造体にコピーしているので、
pre = 0x01
addrの下位バイト = 0x02
addrの上位バイト = 0x03
….
という具合にデータが埋まっている、下の方が正しい値になります。
ところで、Lazuriteのマイコンはlittle endian(リトルエンディアン)なので、下位バイトが先で、上位バイトが次になります。CPUによってはbig endian(ビック エンディアン)もあり、そのCPUは上位バイトが先で、下位バイトが次になります。
さて今回のまとめです。
・同じに見える構造体でも、CPUによってパディングの影響で配列が変わってしまうことがある。
・Lazuriteでは、「__packed 」宣言によってパディングしない構造体を指定することができる。